Ada pernyataan sbb: "Seorang Data Analis bekerja menggunakan data yang sudah diagregasi sehingga tidak berhubungan dengan data pribadi". Benarkah demikian? Artikel ini berusaha untuk menjawab pertanyaan tersebut.
Jawaban singkat : Belum tentu benar!
Jawaban lengkap, silakan baca tulisan berikut.
Dalam suatu dataset hasil agregasi bisa saja data tersebut mengandung data pribadi! Suatu kondisi dataset yang disebut memiliki k-anonymity = 1. Kita akan bahas tentang k-anonymity nanti, tetapi pada prinsipnya itu suatu metrik dari suatu dataset yang mana makin besar nilainya, maka makin sulit seseorang menebak-nebak suatu individu masuk ke dalam baris data yang mana.
Permasalahan kedua dari pernyataan di atas adalah bahwa seorang data analyst dan juga statistician sering kali bekerja menggunakan data mentah yang mana dataset tersebut bisa jadi mengandung data pribadi. Walaupun dia melakukan agregasi dan menampilkan hasilnya dalam bentuk sudah ter-agregasi, namun fakta bahwa dia mengolahnya dari data mentah yang mengandung data pribadi maka sudah bisa dikatakan bahwa dia telah memproses/menggunakan data pribadi. Seharusnya data ini dilakukan proses anonimisasi terlebih dahulu sebelum diserahkan kepada data analyst.
Kita akan bahas proses anonimisasi pada artikel lainnya. Sekarang kita bahas k-anonymity.
Apa yang dimaksud k-anonimity?
k-anonymity adalah konsep dalam data pribadi untuk memastikan bahwa setiap baris data dalam suatu dataset tidak bisa dibedakan dengan paling tidak k-1 baris data lainnya dalam dataset tersebut berdasarkan atribut-atribut dalam dataset.
Atau dalam definisi yang lebih formal disebutkan :
“A release of data is said to have the k-anonymity property if the information for each person contained in the release cannot be distinguished from at least k−1 individuals whose information also appears in the release.”
Istilah k-anonymity ini muncul di dalam domain "data privacy", pertama kali disebutkan dalam karya Latanya Sweeney and Pierangela Samarati pada tahun 1998. Dan sekarang konsep tersebut telah diterima secara umum.
Untuk jelasnya, perhatikan visualisasi data berikut ini yang merupakan data statistik yang diambil dari suatu perusahaan:
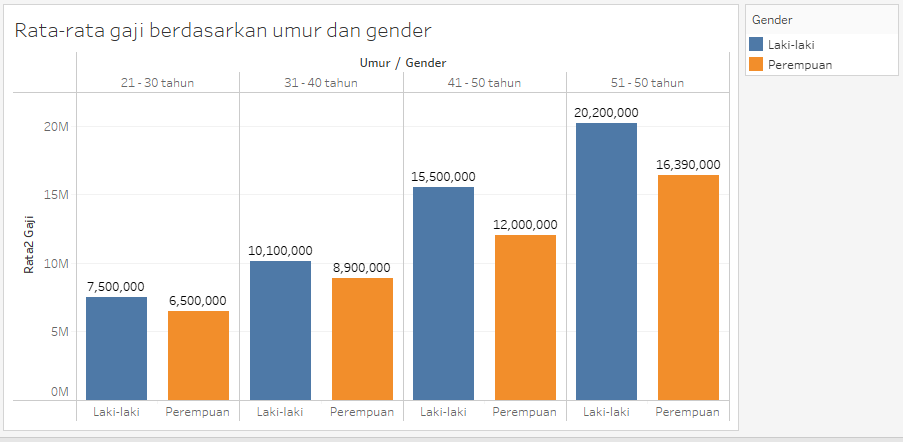
Apakah dalam visualisasi di atas mengandung data pribadi? Yakin tidak ada masalah terkait data pribadi pada visualisasi data di atas? Coba kita lihat underlying data yang digunakan untuk visualisasi data di atas. Mungkin akan terlihat lebih jelas permasalahannya
| Umur | Gender | Rata-rata Gaji |
|---|---|---|
| 21 - 30 tahun | Laki-laki | 7,500,000 |
| 21 - 30 tahun | Perempuan | 6,500,000 |
| 31 - 40 tahun | Laki-laki | 10,100,000 |
| 31 - 40 tahun | Perempuan | 8,900,000 |
| 41 - 50 tahun | Laki-laki | 15,500,000 |
| 41 - 50 tahun | Perempuan | 12,000,000 |
| 51 - 50 tahun | Laki-laki | 20,200,000 |
| 51 - 50 tahun | Perempuan | 15,390,000 |
Bagaimana sekarang? Apakah sudah mulai terlihat ada tanda-tanda data pribadi pada data di atas?
Sama saja bukan? Tidak terlihat ada data-data pribadi pada dataset di atas karena memang k-anonymity pada dataset agregat seperti ini tidak bisa terlihat langsung dari datanya. Tapi coba bayangkan kalau kita adalah salah satu karyawan di perusahaan tersebut yang tahu betul bahwa satu-satunya pegawai perempuan yang berusia 21-30 tahun di sini adalah seorang pegawai bernama Nadya. Gotcha! Kita tahu bahwa gaji Nadya menurut data di atas adalah Rp. 6.500.000!
Beberapa regulasi seperti HIPPA (regulasi data privacy di bidang data kesehatan di Amerika), mengharuskan k-anonimity ≥ 3 sebelum data agregat diijinkan untuk dipublikasikan.
Konsep anonymity akan lebih jelas dipahami jika menggunakan dataset level-individu. Dan sebetulnya memang konsep k-anonymity ini awalnya dibuat untuk dataset individual seperti pada medical record dan data customer, untuk memastikan bahwa data hasil anonimisasi, misalnya dengan menghilangkan nama dan ID pada setiap barisnya, benar-benar menghasilkan dataset yang anonim.
Coba perhatikan data pasien suatu rumah sakit hipotesis sebagai berikut
| Nomor | Nama | Umur | Gender | Dokter | Penyakit |
|---|---|---|---|---|---|
| 1 | ******** | 23 | Perempuan | Dokday | Flu |
| 2 | ******** | 23 | Laki-laki | Gatut | Cantengan |
| 3 | ******** | 23 | Perempuan | Dokbil | Cancer |
| 4 | ******** | 23 | Laki-laki | Dokfun | Cantengan |
| 5 | ******** | 23 | Perempuan | Idhoen | Sakit Gigi |
| 6 | ******** | 23 | Laki-laki | Idhoen | Cantengan |
| 7 | ******** | 30 | Laki-laki | Gatut | Depresi |
| 8 | ******** | 30 | Laki-laki | Dokday | Malaria |
| 9 | ******** | 30 | Perempuan | Idhoen | TBC |
| 10 | ******** | 30 | Laki-laki | Dokfun | Demam Berdarah |
| 11 | ******** | 30 | Perempuan | Dokfun | Frozen Shoulder |
Pasien Perempuan berumur 23 tahun pada data di atas ada 3 record, yaitu nomor 1, 3 dan 5. Sehingga kita tidak bisa menentukan secara pasti pasien nomor berapakah seseorang perempuan yang berusia 23 tahun. Dalam hal ini data tesebut memiliki k-anonymity =3.
Begitu pula, pasien Laki-laki berumur 23 tahun, muncul 3 record yaitu nomor 2,4 dan 6. Dan juga pasien laki-laki berumur 30 tahun ada 3 record (nomor 7,8, dan 10). Keduanya memiliki k-anonymity = 3.
Namun pada pasien perempuan berumur 30 tahun, hanya muncul 2 record yaitu nomor 9 dan 11. Maka dinyatakan memiliki k-anonymity = 2. Dalam satu dataset nilai anonymity terendah menjadi nilai k-anonymity dataset secara keseluruhan (weakest point principle).
Jika sumber data nya menggunakan relational database seperti Oracle, Postgres atau lainnya, tentu mudah saja dengan SQL kita menghitung jumlah row untuk setiap groupnya sbb:
SELECT umur, gender, count(*) as jumlah FROM data_pasien GROUP BY umur, genderSebentar .....
Coba perhatikan lagi data di atas, khususnya untuk pesien laki-laki yang berumur 23 tahun. Semua memiliki penyakit "cantengan"! Atribut penyakit termasuk data yang sensitive, sehingga perlu dilindungi. Dengan dataset di atas, walaupun kita tidak tahu persis pasien nomor berapa itu, tetapi dari data tersebut kalau kita tahu si-A adalah pasien rumah sakit tsb, laki-laki berumur 23 tahun, kita bisa mengambil kesimpulan bahwa dia sakit "cantengan"! Jadi ternyata k-anonymity = 3 tidak menjamin data tsb anonimous. Ini masalah ℓ-diversity
Selain k-anonymity, perlu diperhatikan juga ℓ-diversity. Kita akan bahas di lain artikel
Tags
- Log in to post comments